
In today’s competitive digital environment, digital service providers (DSPs) focus on targeting the right set of customers with personalised marketing campaigns. However, the different approaches to determine the right set of customers such as manual spreadsheet-based statistical modelling and outcome modelling have shown the following limitations:
- Randomised and inaccurate list of target customers
- Lack of granularity on which customers are most likely to respond to marketing campaigns
- Minimum marketing return on investment (ROI)
Demand Side Platforms (DSPs) need to look beyond the traditional approaches and adopt machine learning (ML)-based uplift modelling to identify the right set of target customers. The ML-based uplift modelling enables DSPs to increase the uplift score and helps in gaining granularity in terms of which probable churners have a higher likelihood to respond positively to a personalised campaign, thereby improving marketing efficiency and driving higher incremental revenue, writes Prashant Maloo, a system architect at Prodapt.
Determining the right set of target customers, who have a high probability to respond positively to a marketing campaign, requires using the right type of raw data input to achieve the feature datasets. These feature datasets must be engineered to obtain the most relevant and best features, which can then be used as an input into the AI/ML model.
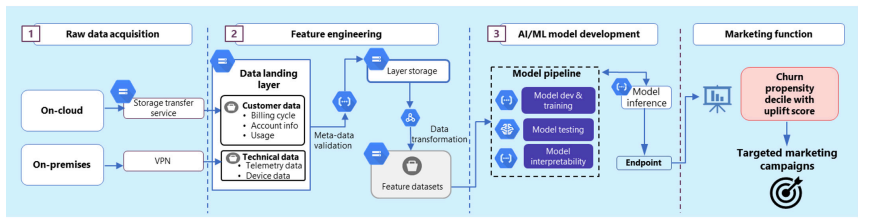
Developing a fully functional uplift model is a complex task and if not strategised and implemented correctly, can fail to provide the required granularity in the target list of customers. This article details the right set of enablers such as raw data acquisition, feature engineering, and AI/ML model development that are crucial for the successful implementation of ML-based uplift modelling.
1) Raw data acquisition:
Select the best raw data to achieve accurate churn propensity and improved uplift.
Acquiring the right set of raw data is the most critical step because it will help in determining the relevant feature datasets, which in turn will enable DSPs to achieve an accurate churn propensity output and a higher uplift score.
Recommendations
- Solution architects and domain experts should collaborate to decide on data aggregation strategies and finalise the type of raw datasets.
- Select the raw data based on the past 2-3 months trends. The historical trends depend on: – Customers’ churn data – Active customers’ feedback – Customer response from marketing campaigns
- Select the raw data having high influencing features such as distance between an active customer and churner, competitor footprint and hourly broadband usage.
- Perform metadata validation daily, as the raw data acquisition is a continuous ongoing process. Metadata validation tools could be built using Python.
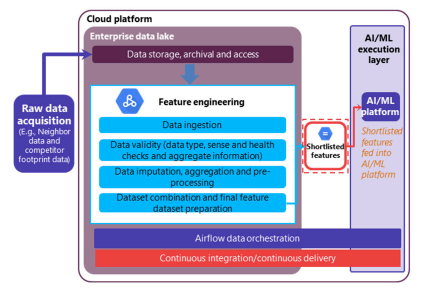
2) Feature engineering (FE):
Utilise data science to process raw data and select the best features.
The raw data, once obtained, must be engineered to get the best feature dataset. With feature engineering, the raw data is transformed into features that better represent the underlying issue to the ML algorithm, resulting in enhanced model accuracy.
Recommendations
- Use the FE model to ingest and analyse the raw data to obtain >3,000 features. The number of features may differ on a case-to-case basis depending on the type of raw data used.
- Execute the feature selection process using the AI/ML platform to select only the best 400-1,000 final features (out of 3,000 features).
- The most critical features for an effective uplift model are listed below:

- The whole FE architecture should be managed on a data orchestration and scheduling platform such as Apache Airflow, which allows the FE data pipeline to be triggered automatically bi-weekly or monthly.
3) AI/ML model development:
Increase the uplift score and target the right set of customers
The features, once obtained, must be fed into the AI/ML engine, which would enable the DSPs to sort the probable churners into deciles with the corresponding uplift score.
Recommendations
- Adopt multiclass classification-based AI/ML model, as a variety of features are analysed to predict the churn.
- Implement custom hyper-parameter tuning before the ML process begins, as it helps in testing different configurations when training the ML model.
- Implement Kubernetes, an open-source container orchestration system, to automate the deployment and management of ML model.
- Run the engineered features through three ML algorithms: i) Variance inflation factor ii) Random forest algorithm iii) XGBoost model
- These algorithms analyse and select the top features required to predict the churn propensity and increase the uplift.
By embracing these enablers, DSPs can achieve a 10%- 18% increase in their uplift score. Furthermore, the return on marketing investment for DSPs would also increase drastically.
Comment on this article below or via Twitter: @ VanillaPlusMag




